Issues
APScheduler
If you check the log files e.g.
~/repo/uwsgi/log/www.hatherleigh.info-scheduler-logger.log
and see the scheduler looping, always Adding job tentatively, then there is
probably an import error with your jobs
e.g schedule_this_function_does_not_exist does not exist in crm.tasks:
scheduler.add_job(
"crm.tasks:schedule_this_function_does_not_exist",
Ember JS
Tip
If Ember repeats the API call many times, then it may be because the view is not returning as many records as expected.
ember-changeset-validations
The import for validations does not work if you use curly brackets
({, }):
import { ContactValidations } from "../../validations/contact"
Don’t use curly brackets e.g:
import ContactValidations from "../../validations/contact"
Add On
If you have a template in an (Embroider) add-on and it isn’t displaying correctly, then try copying it to your project.
You will see errors in the console, which are not displayed when the hbs
file is in the add-on. You can move it back when all of the issues are
resolved.
Data
Unknown bucket from this.store.query:
Assertion Failed: Unknown bucket undefined
Your filter is probably an Object rather than an ID:
filter["contactId"] = this.args.contact
// should be
filter["contactId"] = this.args.contact.id
Embroider
e.g:
webpack 5.75.0 compiled with 3 errors in 6233 ms
Build Error (PackagerRunner) in modifiers/did-insert.js
Module not found: Error: Can't resolve '../../../../app/ember-kb-core/ember-kb-core/node_modules/.pnpm/@[email protected]_7qtfvpmlucc5lcdjv3atxad67a/node_modules/@ember/render-modifiers/modifiers/did-insert' in '$TMPDIR/embroider/351288/project/my-project/front/modifiers/did-insert.js'
Stack Trace and Error Report: /tmp/error.dump.fa33a5f885f8c20b6328bf67fb2f9032.log
To solve the issue, I did:
rm -rf /tmp/embroider/
Note
I got this idea from reading https://github.com/embroider-build/embroider/issues/1116 but it didn’t solve the issue.
rootURL
We were using rootURL in config/environment.js to load assets from the
correct URL on the server (see dist/index.html).
When using Embroider, we also need to update the webpack configuration for
publicAssetURL in ember-cli-build.js e.g:
packagerOptions: {
// publicAssetURL is used similarly to Ember CLI's asset fingerprint prepend option.
publicAssetURL: "/task/",
For more information, see https://github.com/ef4/ember-auto-import/blob/main/docs/upgrade-guide-2.0.md#publicasseturl
Ember Data
I had an issue with Ember Data adapters. For more information, Ember Data
setRouteName
I had this error message when trying to use a route from an addon:
route._setRouteName is not a function
The error was in my route file (addon/routes/workflow-delete.js).
I defined a Controller where I should have defined a Route!
Flowable
Data Types
Our workflow has a total variable with a value of 1481.47.
Calling the form-data REST API (e.g. /service/form/form-data?taskId=93)
throws the following exception:
{
"exception": "java.lang.Double cannot be cast to java.lang.String",
"message": "Internal server error"
}
I am not casting the value to a string, so I think Activiti is storing the data
internally as a Double.
Note
I have no idea why Activiti cannot cast a Double to a String
Solution
I am using the double data type in the workflow, and it is accepted without
any problem. Comparisons are working as long as both data types are a
double e.g:
<activiti:formProperty id="total" name="Invoice Value" type="double" required="true"></activiti:formProperty>
<activiti:formProperty id="seniorLevelValue" type="double" required="true"></activiti:formProperty>
<conditionExpression xsi:type="tFormalExpression"><![CDATA[${total <= seniorLevelValue}]]></conditionExpression>
Issue #2
I am now getting:
"java.lang.Integer cannot be cast to java.lang.String"
Is this because my invoice number is a whole number, but is mapped to a string?
Gateway
If your exclusive gateway is not behaving, check the following:
Check you are using a gateway.
This example task does not use a gateway, so (I don’t think) the engine knows which route to take next:
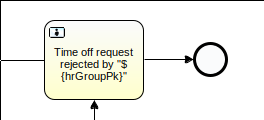
Here is the same example task which has the required exclusive gateway:
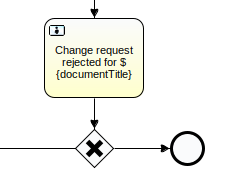
Check the gateway has a Default flow
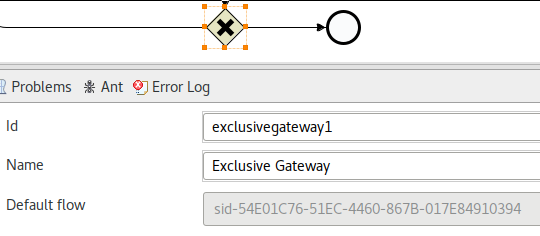
In the XML file, the default gateway will look like this:
default="sid-54E01C76-51EC-4460-867B-017E84910394"
Tip
If the default flow is empty, then I don’t think the gateway works properly.
Group
I was trying to set a group in the workflow:
activiti:candidateGroups="${hrGroupPk}"
And kept getting the Expression did not resolve to a string or collection of strings exception thrown:
ERROR org.activiti.engine.impl.interceptor.CommandContext
- Error while closing command context
org.activiti.engine.ActivitiIllegalArgumentException:
Expression did not resolve to a string or collection of strings
To solve the issue, the group ID must be converted to a string:
# replace this
# result = self.group
# with:
result = str(self.group.pk)
Here is the diff: https://gitlab.com/kb/workflow/commit/fe4816adaf2d1e5194666356b01c538ee6def6cb
Lock
In /var/log/tomcat9/catalina.0000-00-00.log when restarting Tomcat:
liquibase.exception.LockException:
Could not acquire change log lock. Currently locked by ...
From Flowable forum - Liquibase changeLogLock…
To resolve the issue, check the following tables in the Flowable database:
act_app_databasechangeloglock
act_cmmn_databasechangeloglock
act_co_databasechangeloglock
act_dmn_databasechangeloglock
act_fo_databasechangeloglock
flw_ev_databasechangeloglock
If you find a locked record e.g:
select * from flw_ev_databasechangeloglock;
id | locked | lockgranted | lockedby
----+--------+-------------------------+-----------------------
1 | t | 2020-08-16 21:58:45.296 | UKAZU1S213 (10.3.3.4)
Warning
From the link above, Clear the locks only if there is no upgrade running. The question is why Flowable crashed!?
Then you can clear the lock:
UPDATE flw_ev_databasechangeloglock SET LOCKED=FALSE, LOCKGRANTED=null, LOCKEDBY=null where ID=1;
Alfresco
Warning ref CPU usage above 90%:
sudo /opt/alfresco-community/libreoffice/scripts/libreoffice_ctl.sh stop
sudo /opt/alfresco-community/libreoffice/scripts/libreoffice_ctl.sh start
APM
APM didn’t upgrade until I ran the Salt state.
It is also worth checking the release notes.
Celery
AMQP
Note
We use RabbitMQ (AMQP) when we deploy to Windows servers.
If you find Celery wants to use AMQP (amqp/transport.py,
Connection refused), then check you created celery.py in your
project (or example_appname) folder, and that your __init__.py
contains from .celery import app as celery_app. For more information, see
Celery (using Redis) and Celery on Windows
No such transport
Running a Django management command on Windows:
File "C:\inetpub\wwwroot\my-site\venv\lib\site-packages\kombu\transport\__init__.py", line 90, in resolve_transport
raise KeyError('No such transport: {0}'.format(transport))
KeyError: 'No such transport: '
The set_env_test.bat command had the Celery URL in double quotes:
SET CELERY_BROKER_URL="amqp://guest:guest@localhost:5672//"
To fix the issue, I removed the double quotes:
SET CELERY_BROKER_URL=amqp://guest:guest@localhost:5672//
Not Running Tasks
If you find Celery is not running tasks, try the following:
Open Task Manager on Windows and check you have a single instance of
celery.exe running. I don’t know why (or even if) multiple instances cause
a problem, but a single instance has got us processing tasks again.
If your task is in an app, check you are Using the @shared_task decorator
Stalled
If your application stops / stall on a delay, then redis might not be
running:
transaction.on_commit(
lambda: update_contact_index.delay(self.object.pk)
)
I have no idea how long the timeout is… but it never returned for me!
Windows Service
We have a Windows Service for Waitress and Dramatiq.
If they are failing, start by reviewing the Dramatiq notes below…
Then try the following:
I solved the problem (several times) by copying python37.dll from:
\kb\Python37\
to:
C:\Windows\System32\
To see an error message, try running:
\kb\Python38\Lib\site-packages\win32\pythonservice.exe -debug "KB-Software-Dramatiq"
\kb\Python38\Lib\site-packages\win32\pythonservice.exe -debug "KB-Software-Waitress"
Note
This is the code which is run by HandleCommandLine in
win32serviceutil.py. I used this to find the
"pywintypes35.dll" is missing from your computer message which I
fixed by running the next step in these notes.
Try installing pywin32-228.win-amd64-py3.7.exe as a global package using
the installer. The installer runs a script called pywin32_postinstall.py
which copies DLL files to the correct locations.
Note
Running pip install pypiwin32==219 doesn’t seem to run the
pywin32_postinstall.py script, so the service cannot find the DLL
files that it needs! Try running it manually using the globally
installed python.
To debug the service start-up, add ipdb to the code and then run:
python celery_service_worker.py debug
cron
If a cron script in /etc/cron.d has a . in the file name, then it will
not run! (configs with dots in file name not working in /etc/cron.d)
devpi
Certificate
Firewall
If you get 404 errors when attempting to create a certificate using HTTP validation and LetsEncrypt, then check your Firewall. It might not allow incoming connections to port 80 from the LetsEncrypt servers.
To workaround the issue, use LetsEncrypt - DNS to generate the certificate.
python 2
I was getting SSL
certificate verify failederrors when usingdevpi(which useshttpieandrequests). To solve the issue, usedevpiwith a python 3 virtual environment (not python 2).
Could not find a version that satisfies the requirement
I was trying to install Django 3.0.5 and kept getting this error:
Could not find a version that satisfies the requirement django==3.0.5
(from -r requirements/base.txt (line 10))
(from versions: 1.1.3, 1.1.4, 1.2, 1.2.1, 1.2.2, 1.2.3, 1.2.4, 1.2.5, 1.2.6,
...
2.2.3, 2.2.4, 2.2.5, 2.2.6, 2.2.7, 2.2.8, 2.2.9, 2.2.10, 2.2.11, 2.2.12)
ERROR: No matching distribution found for ...
Version 3.0.5 was not listed in the versions. I updated devpi thinking
there was a problem with our PyPI server, but it didn’t help.
We were running Python 3.5.2 on our CI server. The Django 3.0 release notes says:
Django 3.0 supports Python 3.6, 3.7, and 3.8. We highly recommend and only officially support the latest release of each series. The Django 2.2.x series is the last to support Python 3.5.
To solve the issue, I upgrade the Docker container to use Ubuntu 18.04 (Upgrade container to Ubuntu 18.04).
Index
If you have a local PyPI server, and you do not want to use it, then
comment out index-url in:
~/.pip/pip.conf
Killed
My devpi-server --import was not completing and finishing with a Killed
message. To solve this issue, increase the available memory on the server.
I increased from 1GB to 2GB and the import completed successfully.
Django
CORS
To solve this issue, we replaced:
router = routers.DefaultRouter()
with:
router = routers.DefaultRouter(trailing_slash=False)
The solution was prompted by this Stackoverflow article, React to django CORS issue
Sometimes it happens because of the url pattern. Please check the url pattern whether it requires a slash at the end or not. Try using ‘login’ instead of ‘login/’
current transaction is aborted
If you get this error when running unit tests:
django.db.utils.InternalError: current transaction is aborted, commands ignored until end of transaction block
Add --create-db to recreate the database.
Thank you to Django+Postgres: “current transaction is aborted
for the solution.
Remove the admin app
If you get this error:
django.urls.exceptions.NoReverseMatch: 'admin' is not a registered namespace
Then you may need to replace the staff_member_required decorator…
For more information, see Django View…
Testing File Field
django.core.exceptions.SuspiciousFileOperation:
The joined path (/2020/06/None-example.dat) is located outside of the base
path component (/home/patrick/dev/app/record/media-private)
To solve this issue, load the test file from the MEDIA_ROOT folder e.g:
from django.conf import settings
from pathlib import Path
file_name = Path(
settings.BASE_DIR, settings.MEDIA_ROOT, "data", "1-2-3.doc"
)
record = Record.objects.create_record(
"testing", user, file_name=file_name
)
Django Compressor
I had an issue where relative images in css files were not being found e.g:
url(../img/logo-fill.png)
Django Compressor is supposed to convert relative URLs to absolute e.g:
url('https://hatherleigh-info-test.s3.amazonaws.com/dash/img/logo-fill.png?ae4f8b52c99c')
The compress management command creates a manifest file listing the files
it creates. On the web server this can be found in:
./web_static/CACHE/manifest.json
On Amazon S3 it is in the CACHE folder.
You can look at the manifest files to find the name of the generated CSS file and look in this file to see if the relative URLs are converted to absolute.
You can use the browser developer tools to see which CSS file is being used.
To solve the issue, I checked the generated CSS file and the links were not
relative. I then ran compress and checked the generated CSS file again and
the links were absolute. I re-started the Django project on the server and all
was OK.
Tip
I also uninstalled django-storages-redux and reinstalled the old
version:
(git+https://github.com/pkimber/django-storages-py3.git@py3#egg=storages)
… but I don’t think that made a difference?!
Migrations
InvalidBasesError:
django.db.migrations.exceptions.InvalidBasesError:
Cannot resolve bases for [<ModelState: 'web.DefaultPage'>]
This can happen if you are inheriting models from an app with migrations
(e.g. contrib.auth) in an app with no migrations; see
https://docs.djangoproject.com/en/5.1/topics/migrations/#dependencies
To solve the issue, create the migrations folder with an __init__.py
file:
mkdir web/migrations
touch web/migrations/__init__.py
For more information, see InvalidBasesError: Cannot resolve bases for [<ModelState: ‘users.GroupProxy’>]
Django REST Framework
I created a serializer (using the serializers.Serializer class), but was
getting the following error message when calling serializer.data:
::
TypeError: ‘method’ object is not iterable
The issue was caused by a _data method which I put in the serializer.
This clashes with an attribute of the Serializer class!!!
To solve the issue, I renamed the _data method to _workflow_data.
Django REST Framework JSON API
Could not satisfy the request Accept header
Trying to upload from Ember to Django using ember-file-upload,
https://ember-file-upload.pages.dev/
{
"errors": [
{
"detail": "Could not satisfy the request Accept header.",
"status": "406",
"source": {
"pointer": "/data"
},
"code": "not_acceptable"
}
]
}
To solve the issue, add accepts: ["application/vnd.api+json"]
const response = await file.upload(
uploadUrl,
{ accepts: ["application/vnd.api+json"], headers: headers }
);
TemplateDoesNotExist: django_filters/rest_framework/form.html
Browsing to http://localhost:8000/api/0.1/contacts in Firefox (or Chrome):
TemplateDoesNotExist at /api/0.1/contacts - django_filters/rest_framework/form.html
We didn’t get the error using httpie e.g:
http GET "http://localhost:8000/api/0.1/contacts"
To solve the issue add django_filters to THIRD_PARTY_APPS e.g:
# example_contact/base.py
THIRD_PARTY_APPS = (
# add django_dramatiq to installed apps before any of your custom apps
"django_dramatiq",
"django_filters",
For more details, see TemplateDoesNotExist: django_filters/rest_framework/form.html
unexpected keyword argument ‘partial’
update() got an unexpected keyword argument 'partial'
To resolve this issue, change the update parameters in the view set:
# from
# def update(self, request, pk=None):
# to
def update(self, request, *args, **kwargs):
Docker
To cleanup Docker containers, run the following as root:
docker system prune -a
Tip
May be safer to run it without the -a as I had to
reinstall gitlab-runner!
There were loads of files in the following folder, so I removed them:
Warning
This broke the Docker container and I had to restart the server to fix it.
cd /var/lib/docker/volumes
ls -d */ | xargs rm -rf
Dramatiq
Service not Running
Try running dramatiq from the command line:
c:
cd \kb\navigator-connector
set_env_variables.bat
c:\kb\navigator-connector\venv\Scripts\dramatiq.exe
We had an Access is denied message when running dramatiq.exe.
The resolution was to add a
local exclusion for that folder within Microsoft Defender.
For more information, see https://www.kbsoftware.co.uk/crm/ticket/5668/
gevent
Compile fails and I can’t find the required dependencies:
x86_64-linux-gnu-gcc: error: src/gevent/libev/corecext.c: No such file or directory
x86_64-linux-gnu-gcc: fatal error: no input files
compilation terminated.
error: command 'x86_64-linux-gnu-gcc' failed with exit status 1
To fix this issue, upgrade pip so it can install wheels.
pika
Error:
ModuleNotFoundError: No module named 'pika'
Make sure django_dramatiq is first in your list of THIRD_PARTY_APPS.
If this doesn’t help, then make sure you have configured your settings files
correctly for Dramatiq (don’t forget dev_test.py).
For details, see Configure.
Dropbox
When testing the scripts:
No protocol specified
!! (Qt:Fatal) QXcbConnection: Could not connect to display :0
To stop this error, use a headless connection i.e. ssh into the computer or use
a separate console. This will still be an issue if you have a GUI and you
sudo to a user who is not running a GUI.
Backup
If the backup server runs out of space:
Lots of directories in
/tmpcalled.dropbox-dist*(10Gb)Backup folder for the site had lots of
.sqlfiles from presumably failed backup (3Gb)Check the
/home/web/tmpfolder. Malcolm deleted this, which freed 1.8G of space!Check the
/home/web/temp/folder and track down large files:du -sh *
You could also try (it didn’t free any space for me):
rm -r /home/web/repo/files/dropbox/<site name>/Dropbox/.dropbox.cache/*
Duplicity
gio
If you get this error:
No module named gio
Then:
apt-get install python-gobject-2
Symbolic Links
Duplicity does NOT backup symbolic links… or the contents of symbolic links.
ElasticSearch
For version 6.x issues, see:
Connection marked as dead
Errors from the ElasticSearch client saying:
%s marked as dead for %s seconds
The code can be seen here: https://github.com/rhec/pyelasticsearch/blob/master/pyelasticsearch/client.py#L241
My thought is that the pyelasticsearch client is timing out when the
cron task re-indexes the data (there are lots of records, so I would expect
this to take some time). The connections are pooled, and time-out, so the
connection is marked as dead.
To see if this is the problem (or not), I have added BATCH_SIZE and
TIMEOUT to the settings:
HAYSTACK_CONNECTIONS = {
'default': {
'BATCH_SIZE': 100,
'ENGINE': 'haystack.backends.elasticsearch_backend.ElasticsearchSearchEngine',
'INDEX_NAME': '{}'.format(SITE_NAME),
'TIMEOUT': 60 * 5,
'URL': 'http://127.0.0.1:9200/',
},
}
For documentation on these settings: http://django-haystack.readthedocs.org/en/v2.1.0/settings.html
The following signatures couldn’t be verified
Trying to install the Salt state for Elastic:
ID: deb [signed-by=/etc/apt/keyrings/elasticsearch-keyring.gpg arch=amd64] https://artifacts.elastic.co/packages/8.x/apt stable main
Failed to configure repo 'deb [signed-by=/etc/apt/keyrings/elasticsearch-keyring.gpg arch=amd64] https://artifacts.elastic.co/packages/8.x/apt stable main': W: GPG error: https://artifacts.elastic.co/packages/8.x/apt stable InRelease: The following signatures couldn't be verified because the public key is not available: NO_PUBKEY D27D666CD88E42B4
E: The repository 'https://artifacts.elastic.co/packages/8.x/apt stable InRelease' is not signed.
To solve the issue, Download and install the public signing key:
wget -qO - https://artifacts.elastic.co/GPG-KEY-elasticsearch | sudo gpg --dearmor -o /usr/share/keyrings/elasticsearch-keyring.gpg
Move the key to the location expected by the Salt state:
sudo mv /usr/share/keyrings/elasticsearch-keyring.gpg /etc/apt/keyrings/elasticsearch-keyring.gpg
I then had to apt remove elasticsearch
and then apt install elasticsearch before it would work.
Re-apply the Salt state…
Tip
I am sure it would be easy to update the Salt state, but I am feeling tired this evening.
fabric
env is not set when you use run (with Connection).
To resolve the issue, add inline_ssh_env to the Connection
constructor e.g:
with Connection(domain_deploy, user, inline_ssh_env=True) as ctx:
ctx.run(
"cd {site_folder} && {venv} {manage} {command}".format(**param),
env=env,
replace_env=True,
echo=True,
)
Warning
The inline_ssh_env functionality does not perform any shell
escaping on your behalf!
For more information, see fabric, Connection, __init__
git
git clone fails with “fatal: Out of memory, malloc failed” error
To install the Salt master on a Linux server with less resources, I created a swap file:
df -v
swapon --show
free
fallocate -l 1G /swapfile
ls -lh /swapfile
sudo chmod 600 /swapfile
ls -lh /swapfile
mkswap /swapfile
swapon /swapfile
swapon --show
free
Tip
Instructions from How To Add Swap Space on Ubuntu 16.04
GitLab
CI
If you find Continuous Integration (CI) is running tests from other apps, then
check the project setup.cfg file to make sure src is included in the
norecursedirs section. For details, see Continuous Integration.
Push an existing Git repository
If following the instructions to push an existing project to a new repo e.g:
cd existing_repo
git remote rename origin old-origin
git remote add origin git@gitlab.com:kb/simple-site.git
git push -u origin --all
git push -u origin --tags
And you get remote rejected errors:
To gitlab.com:kb/simple-site.git
! [remote rejected] 5419-wagtail -> 5419-wagtail (pre-receive hook declined)
! [remote rejected] 5419-wagtail-tailwind-ui -> 5419-wagtail-tailwind-ui (pre-receive hook declined)
! [remote rejected] master -> master (pre-receive hook declined)
error: failed to push some refs to '[email protected]:kb/simple-site.git'
Update your permissions in the Members section to Maintainer.
Google
Captcha - Not Submitted
The Captcha data is not submitted when using JavaScript to POST a form e.g:
<form id="loginForm" action="." method="POST" class="flexform">
<a onClick="loginForm.submit()" class="button">Reset Password</a>
To solve the issue (field is required), just use a button e.g:
<button class="button">Reset Password</button>
Captcha - element.form.submit is not a function
recaptchaFormSubmit:
TypeError: element.form.submit is not a function
To solve the issue, remove name="submit" from the button e.g:
<button type="submit" ...
JavaScript
node-sass will not install
This seems to be a very common error:
Error: EACCES: permission denied, mkdir '/usr/lib/node_modules/node-sass/.node-gyp'
The solution seems to be as follows:
npm -g --unsafe-perm install node-sass
LetsEncrypt
404
If you get 404 not found, then check you sudo service nginx reload.
certbot upgrade
09/03/2021, I think the new version of certbot may have caused some issues with existing certificate renewals. I have deleted the old certificates for www.hatherleigh.info and requested new certificates by running the following:
sudo -i
cd /etc/letsencrypt
rm -r */www.hatherleigh.info*
/home/web/opt/init-letsencrypt www.hatherleigh.info hatherleigh.info
sudo nginx -t # to check config ok
sudo systemctl reload nginx
git
If you get an error similar to this from salt state.apply:
ID: letsencrypt-git
Function: git.latest
Name: https://github.com/letsencrypt/letsencrypt
Result: False
Comment: Repository would be updated from 2434b4a to f0ebd13, but there are
uncommitted changes.
Log onto the affected server:
sudo -i
cd /opt/letsencrypt
git status
# checkout the file which is listed (in my case "letsencrypt-auto)
git checkout letsencrypt-auto
git status # should show nothing
init-letsencrypt - memory
virtual memory exhausted: Cannot allocate memory
Certbot has problem setting up the virtual environment.
Based on your pip output, the problem can likely be fixed by
increasing the available memory.
We solved the issue by creating a temporary swap file and then retrying the
init-letsencrypt command:
sudo fallocate -l 1G /swapfile
sudo chmod 600 /swapfile
sudo mkswap /swapfile
sudo swapon /swapfile
Check the swap status with:
sudo swapon -s
Note
I can’t solve the issue, so referring to a colleague… For more information, see https://github.com/certbot/certbot/issues/1081 https://certbot.eff.org/docs/install.html#problems-with-python-virtual-environment
init-letsencrypt - datetime
ImportError: No module named datetime
To solve the issue:
rm -r /home/patrick/.local/
init-letsencrypt - _remove_dead_weakref
I got this error after upgrading to Ubuntu 18.04:
Error: couldn't get currently installed version for /opt/eff.org/certbot/venv/bin/letsencrypt:
...
ImportError: cannot import name _remove_dead_weakref
To solve the issue:
rm -rf /opt/eff.org/certbot/venv/
# run your ``letsencrypt`` command
# /opt/letsencrypt/letsencrypt-auto renew --no-self-upgrade
service nginx restart
renew
If LetsEncrypt is trying to renew old sites, then remove them from:
/etc/letsencrypt/renewal/
SSL Stapling Ignored
Malcolm says that stapling needs a newer version of nginx.
Mail
SparkPost - Blacklisted
Using http://www.mail-tester.com/ we found our domain was blacklisted. The
mail app has a facility for sending a test email (browse to /mail/create/).
We emailed SparkPost, and they sent the following advice:
Thank you for reporting the blacklist issue!
If you look at the raw reason provided:
522 email sent from spmailtechn.com found on industry URI blacklists
on 2017/05/10 18:11:12 BST, please contact your mail sending service or use
an alternate email service to send your email.
Guide for bulk senders www.bt.com/bulksender
… it is the domain spmailtechn.com that has been blacklisted and not the
IP. Your messages are containing spmailtechn.com in the headers because
you haven’t set-up a custom bounce domain yet. In order to do so, you can find
more information through following link:
https://support.sparkpost.com/customer/portal/articles/2371794
Adding a custom bounce domain to your account will also remove
spmailtechn.com from your headers and help fully brand all of your emails
and also protect you from other senders on SparkPost.
We did the following:
Added a DMARC record to our Digital Ocean account:
TXT / _dmarc.kbsoftware.co.uk / returns v=DMARC1; p=none"
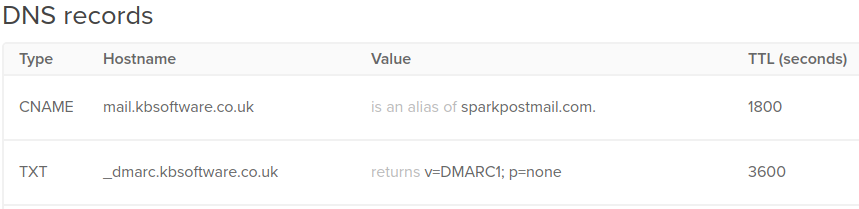
Added a CNAME record to our Digital Ocean account:
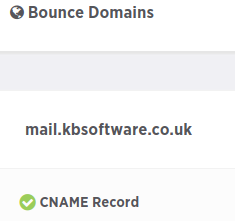
mail.kbsoftware.co.uk / is an alias of sparkpostmail.com

Added bounce.kbsoftware.co.uk as a Bounce Domain in Sparkpost using
Create a separate bounce subdomain:
MailChimp/Mandrill
Received Email Layout Doesn’t Match MailChimp Template
When the template is sent from MailChimp to Mandrill, layout changes are made to the HTML that results in the body text of the received email spilling out beyond the left and right edges of the header image.
To resolve this, the HTML code for the ‘templateContainer’ should be set to 550px, e.g. for the ‘qanda_answer_publish’ template, line 662 should read:
<table border="0" cellpadding="0" cellspacing="0" width="550px" class="templateContainer">
with the <width> tag set to 550px.
The HTML code for the main table layout style should also have the table
tag set to:
table align="left"totable align="center"
wdith="100%"should be removed - this keeps the body text just inside the margins of the table and headers
We emailed MailChimp about this issue, and they replied with this information:
Jumping right in, this is a known issue where the Transactional Email parser has mis-encoded some of the template’s styles when it’s synced over from the Mailchimp account. Unfortunately, the template transfer process is imperfect since many snippets of HTML are explicitly designed for how we use templates in our Mailchimp campaigns, and encoding issues like this can arise. We are working to improve it, but there are currently some things like this that may need to be manually fixed in the HTML. I’ve passed your case of this issue to our developers so they can reference it when they prioritize their work.
I know it’s not the most ideal, but in this case, you’ll want to use the Transactional Email template editor (or you could paste the code into a text editor, then paste it back to a template in Transactional Email) to fix any pieces of code like this that aren’t being encoded and sent over correctly. You would then want to make edits for that particular template only in Transactional Email going forward, as resending the template from Mailchimp would override the current code within Transactional Email for that template, and you’d need to redo those fixes.
If you need to have the template available on both platforms, you could also create a custom-coded template in Mailchimp using the live, working code from Transactional Email > use that template going forward and push changes into Transactional Email made in that specific custom-coded Mailchimp template. That way, the Mailchimp users can utilize the working code and push changes.
Microsoft Azure
Open ID Connect - Need admin approval
If you get prompted with Need admin approval:
Then be sure to set API permissions…
Microsoft Office
Outlook - Why is Outlook Not Showing All Emails?
Filters and Search:
If you have applied any filters or search criteria, that might be limiting the emails you see.
Incorrect Email Filter Settings
One common reason behind the Outlook not showing all emails issue is the presence of incorrect email filter settings. Outlook allows users to apply filters based on criteria such as date, sender, or subject. If you have inadvertently set filters that exclude certain emails from the view, this could be the reason for missing emails. To resolve this, follow these steps:
Step 1: Click on the “View” tab in Outlook.
Step 2: Select the “View Settings” option when you find it.
Step 3: Navigate to the “Filter” tab and review the applied filters. Clear any filters that might be causing the issue.
For more information, see 6 Easy Solutions - Fix Outlook Not Showing All Emails Issue
Microsoft SQL Server
When using the django-mssql-backend requirement and an ENGINE of
sql_server.pyodbc in a Django project, you may see these errors:
ModuleNotFoundError: No module named 'sql_server'
'sql_server.pyodbc' isn't an available database backend
I think you can safely ignore this as it still seems to work fine…!?
nginx
502 Bad Gateway
This is a general error. Find the cause by looking in the following files:
sudo -i -u web
# check the files in:
tail -f ~/repo/uwsgi/log/hatherleigh_info.log
sudo -i
tail -f /var/log/nginx/error.log
# check the log files in:
tail -f /var/log/supervisor/
bind() to 0.0.0.0:80 failed
nginx won’t start and /var/log/nginx/error.log shows:
[emerg]: bind() to 0.0.0.0:80 failed (98: Address already in use)
[emerg] 15405#0: bind() to 0.0.0.0:443 failed (98: Address already in use)
When I stopped the nginx service, I could still see the ports being used:
lsof -i :80
lsof -i :443
From bind() to 0.0.0.0:80 failed, killing the users of the port, sorted the issue:
sudo fuser -k 80/tcp
sudo fuser -k 443/tcp
Note
I am not over happy about this solution. But… I guess the processes were started somehow and had not been stopped?
failed (13: Permission denied) using sendfile
sendfile wasn’t working, and the following message appeared in
/var/log/nginx/error.log:
2017/05/18 17:34:30 [error] 1835#1835: *315 open()
"/home/web/repo/files/www.hatherleigh.info/document.docx"
failed (13: Permission denied),
client: 80.234.181.37, server: www.hatherleigh.info,
request: "GET /dash/document/issue/version/3/download/ HTTP/1.1",
upstream: "uwsgi://127.0.0.1:3040", host: "www.hatherleigh.info"
The www-data user didn’t have permission to read the file. The permissions
were -rw-------.
To solve the problem, add the following to your settings/production.py
file:
FILE_UPLOAD_PERMISSIONS = 0o644
Django will then create files with -rw-r--r-- permissions and all will be
well.
For more information, see Django Media.
no python application found, check your startup logs for errors
This issue was missing environment variables e.g. NORECAPTCHA_SITE_KEY.
I was running tail on the log file for the web application
e.g. ~/repo/uwsgi/log/www.hatherleigh.info-uwsgi.log, and I think the
error was further up the page (so use vim next time to check).
I found the error by trying to run a management command e.g.
www.hatherleigh.info.sh help and it showed the error. Added the missing
environment variables to the vassal and all was fine.
NPM
npm install
npm ERR! code ENOLOCAL
npm ERR! Could not install from "app/ember-addon" as it does not contain a package.json file.
One of the dependencies of the project had a file dependency on
ember-addon i.e:
"@kb/ember-addon": "file:../../../app/ember-addon"
To fix the issue, replace the file dependency with a packaged version e.g:
"@kb/ember-addon": "^0.0.21",
npm link
I couldn’t get npm link to work, so I installed from the folder:
npm i ../../../app/ember-addon/
404 Not Found
If you get this error:
npm ERR! code E404
npm ERR! 404 Not Found - GET https://registry.npmjs.org/@kb/work - Not found
npm ERR! 404
npm ERR! 404 '@kb/work@^0.0.2' is not in the npm registry.
Then the issue may not be related to your Package Registry.
I thought npm was looking in the wrong place i.e. not our private registry
(i.e. npm config set @kb:registry ..., see npm package for
more information).
The issue was… I had the wrong name for the addon. In the example above,
@kb/work should have been @kb/ember-work.
PDFObject
From Failed to load PDF document, to fix it, I changed:
response['Content-Disposition'] = "attachment; filename={}".format(
to:
response['Content-Disposition'] = "inline; filename={}".format(
PHP (php) FPM
We were seeing errors in /var/log/nginx/error.log:
2021/12/04 17:30:09 [crit] 7603#7603: *1 connect() to unix:/run/php/fpm-www.hatherleigh.info.sock failed (2: No such file or directory) while connecting to upstream,
To solve this issue, I re-started the server, but it may have been easier to:
systemctl restart php7.4-fpm.service
PostgreSQL
Certificates
From Host-based snakeoil certificates in Ubuntu
could not load server certificate file "/etc/ssl/certs/ssl-cert-snakeoil.pem":
2025-01-07 11:43:23 GMT FATAL: could not load server certificate file "/etc/ssl/certs/ssl-cert-snakeoil.pem": No such file or directory
2025-01-07 11:43:23 GMT LOG: database system is shut down
To solve the issue:
sudo apt install ssl-cert
sudo make-ssl-cert generate-default-snakeoil --force-overwrite
Warning
I don’t know why this is suddenly an issue. I did a clean install today (January 2025) and the certificates do not exist!
plpgsql
must be owner of extension plpgsql
To fix the issue (on your development workstation only):
alter role patrick superuser;
psycopg - AttributeError
I received this error when upgrading psycopg:
AttributeError: module 'psycopg_binary.pq' has no attribute 'PGcancelConn'
To solve the error, delete the virtual environment and re-install the requirements.
Resource
apt install pgtop
# this example database is using PGBouncer
pg_top -h localhost -p 6432 -d www_kbsoftware_couk -U www_kbsoftware_couk
Ubuntu 14.04 LTS
Warning
Check you have a backup of all databases on your development machine.
If you have upgraded from a previous version of Ubuntu running Postgres 9.1, you might need to completely remove the old version:
sudo apt-get purge postgresql-9.1
record app
If the conversion isn’t working, then it might be because LibreOffice is running on your Desktop.
Shut it down and the conversion should succeed. The error message will probably be: Cannot find converted file.
python
ImportError: No module named ‘example_my_app_name’
When running pytest or django-admin, I get:
ImportError: No module named 'example_my_app_name'
This looks like the same issue: https://github.com/pytest-dev/pytest-django/issues/1019
To solve the problem, I copied manage.py to the root folder.
Note
django-admin still doesn’t work.
Use python manage.py instead.
The system cannot move the file to a different disk drive
Trying to move a file to a Windows UNC path…
using shutil.copy or shutil.move
or replace ( from pathlib.Path):
[WinError 2] The system cannot find the file specified: '\\\\KBAZ00001\\Watch\\honeydown.png'
The only solution I can find is from Python 3’s pathlib Module: Taming the File System e.g:
import pathlib
source = pathlib.Path(from_file_path)
destination = pathlib.Path(to_file_path)
with destination.open(mode="xb") as fid:
fid.write(source.read_bytes())
virtualenv using python3 stuck on setuptools, pip, wheel
From setting up environment in virtaulenv using python3 stuck on setuptools, pip, wheel
1. The first solution, was to create the virtualenv using Ubuntu installed
packages i.e:
python3 -m venv venv-fabric
The second solution (for a python 2 virtual environment is to update the system packages:
sudo -i
pip install --upgrade virtualenv
pip install --upgrade pip
# Ctrl D (no longer root)
virtualenv -v --python=python2.7 venv-fabric
The third solution is to use the
--no-cache-dirparameter e.g:
pip install --no-cache-dir -r requirements/local.txt
Remote Desktop
If you are having issues connecting Using Remmina, then try removing the User name and Password. This will help you see if the issue is to do with connection or authentication.
Restic
From 0.8.3 Fatal: unable to create lock in backend: invalid data returned:
Fatal: unable to create lock in backend: load <lock...>: invalid data returned
To solve the issue, I deleted the lock from the command line e.g:
ssh 123@usw-s011.rsync.net rm restic/www.hatherleigh.info/backup/locks/811...
Free Space
If you reduce the retention periods using --keep-last, --keep-hourly,
--keep-daily, --keep-weekly, --keep-monthly etc, then the space used
will not reduce unless you prune the repository e.g:
/home/web/opt/restic -r sftp:[email protected]:restic/www.hatherleigh.info/backup prune
/home/web/opt/restic -r sftp:[email protected]:restic/www.hatherleigh.info/files prune
unsupported repository version
All restic commands display this error message:
Fatal: config cannot be loaded: unsupported repository version
The repository was created using restic 0.16.4 (probably in V2 format).
To solve the issue, remove the repository folders and recreate using an
older version e.g. restic 0.12.1
From Upgrading the repository format version, the repository format version 2 is only readable using restic 0.14.0 or newer.
Tip
For more information, see Ticket 6107
rsync.net
When I run:
ssh 123@usw-s001.rsync.net ls -la
I am getting the following message:
Unable to negotiate with 170.23.45.250 port 22: no matching host key type found.
Their offer: ecdsa-sha2-nistp256,ssh-ed25519,rsa-sha2-512,rsa-sha2-256,ssh-rsa
To solve the issue, I removed ~/.ssh/config (which contained):
Host *.rsync.net
HostkeyAlgorithms ssh-dss
Tip
For more information, see Ticket 7300 and the ticket where
HostkeyAlgorithms was introduced, Ticket 2626 on 28/09/2017.
Salt
debug
To run the master in the foreground, stop the service, then:
salt-master -l debug
To run the minion in the foreground, stop the service, then:
salt-minion -l debug
doesn't support architecture 'i386'
When adding the following to /etc/apt/sources.list.d/saltstack.list:
deb http://repo.saltstack.com/apt/ubuntu/18.04/amd64/latest bionic main
You may get an error:
N: Skipping acquire of configured file 'main/binary-i386/Packages' as repository 'http://repo.saltstack.com/apt/ubuntu/18.04/amd64/latest bionic InRelease' doesn't support architecture 'i386'
To solve this issue, insert [arch=amd64]:
deb [arch=amd64] http://repo.saltstack.com/apt/ubuntu/18.04/amd64/latest bionic main
env
I took a long time trying to find the fix for this issue:
Jinja variable 'env' is undefined
I solved it by renaming the variable. I don’t know… but I think perhaps
env is a reserved name in Salt?
Firewall
Note
For Ubuntu only…
On the master and minion, open the Firewall for Salt:
ufw allow salt
Java
Getting a weird error (which I don’t really understand):
Cannot find a question for shared/accepted-oracle-license-v1-1
To solve the issue, I ran the following:
# # this showed the issue
# /bin/echo /usr/bin/debconf shared/accepted-oracle-license-v1-1 seen true | /usr/bin/debconf-set-selections
error: Cannot find a question for shared/accepted-oracle-license-v1-1
# # to solve the issue
# /bin/echo /usr/bin/debconf shared/accepted-oracle-license-v1-1 select true | /usr/bin/debconf-set-selections
# /bin/echo /usr/bin/debconf shared/accepted-oracle-license-v1-1 seen true | /usr/bin/debconf-set-selections
Jinja variable is undefined
Trying to add a variable to the context of a Jinja template:
Unable to manage file: Jinja variable 'backup' is undefined
I think the issue was the variable name. I tried backup and apple and
they both failed. I renamed backup to enable_backup and it worked!
Minion ID
To set the minion id:
# /etc/salt/minion
id: cloud-a
# re-start the minion and accept the key on the master
service salt-minion restart
Note
Might be worth checking out this article instead of editing the minion id: http://docs.aws.amazon.com/AWSEC2/latest/UserGuide/set-hostname.html
None issues in template variables
For information, see When passing None to a template, the variable will be set to a string
pillar - refresh
We received this error message:
Specified SLS 'sites.drop-temp' in environment 'base' is not available on the salt master
To solve the issue, refresh the Salt pillar on all of your minions:
salt '*' saltutil.refresh_pillar
For more information, see Pillar
virtualenv.managed
I couldn’t get virtualenv.managed working with python 3, so I ended up following the instructions in Using Salt with Python 3 and Pyvenv
Here is the working Salt state: virtualenv using pyvenv
Selenium
If you have issues with Selenium and Firefox, then try the following:
pip install -U selenium
The following issue with chromedriver (v2.22):
File "/usr/local/lib/python2.7/dist-packages/selenium/webdriver/chrome/webdriver.py", lin 82, in quit
self.service.stop()
File "/usr/local/lib/python2.7/dist-packages/selenium/webdriver/chrome/service.py", line 97, in stop
url_request.urlopen("http://127.0.0.1:%d/shutdown" % self.port)
File "/usr/lib/python2.7/urllib2.py", line 154, in urlopen
return opener.open(url, data, timeout)
File "/usr/lib/python2.7/urllib2.py", line 429, in open
response = self._open(req, data)
File "/usr/lib/python2.7/urllib2.py", line 447, in _open
'_open', req)
File "/usr/lib/python2.7/urllib2.py", line 407, in _call_chain
result = func(*args)
File "/usr/lib/python2.7/urllib2.py", line 1228, in http_open
return self.do_open(httplib.HTTPConnection, req)
File "/usr/lib/python2.7/urllib2.py", line 1198, in do_open
raise URLError(err)
urllib2.URLError: <urlopen error [Errno 111] Connection refused>
Was resolved by updating the version of chromedriver to v2.24.
SOLR
The current version of Haystack has an issue with the simple_backend.py:
https://github.com/toastdriven/django-haystack/commit/49564861
To temporarily fix the issue:
cdsitepackages
vim +67 haystack/backends/simple_backend.py
Edit the code so that it matches the fixed version on GitHub i.e:
for field in model._meta.fields:
Sphinx
The sphinx-rtd-theme has an issue rendering bullet points:
To solve this issue, install these requirements:
sphinx==6.1.1
sphinx-rtd-theme==1.2.0rc2
Tailwind
If Tailwind fails to render correctly when used with Ember and pnpm, then
try deleting pnpm-lock.yaml before running:
rm -rf dist/ node_modules/; and pnpm install; and pnpm start
Ubuntu
Clearing “System Problem Detected” messages
Sometimes historical “System Problem Detected” message re-appear when Ubuntu is started.
For example a problem with the chrome browser may not be reported to Ubuntu because the Chrome is not a supported package.
These message are from files stored in the /var/crash directory.
Investigate old crash messages
Change to the crash reporting directory as follows:
cd /var/crash
View the files in the directory as follows:
ls -al
Files that end with .crash are ascii files containing the crash report
detail. You can view them with your favourite editor (e.g. vim, nano or
gedit). Some crash reports are readable by root only so you may need to use
sudo to be able to view them.
To use vim type:
sudo vim *.crash
To use nano type:
sudo nano *.crash
To use gedit type:
gksu gedit *.crash
You’ll be prompted for your password and on successful entry go to your editor
Delete historical crash messages
To delete historical crash messages type
sudo rm /var/crash/*
Any new crash messages that appear after that should be investigated.
uwsgi
It seems that a new cloud server using python 3 doesn’t install uwsgi
correctly into the virtual environment.
Check the supervisor error log for uwsgi:
/var/log/supervisor/uwsgi-stderr
If you get the following:
exec: uwsgi: not found
Then:
sudo -i -u web
cd /home/web/repo/uwsgi
. venv_uwsgi/bin/activate
pip install uwsgi==2.0.1
The version of uwsgi can be found in
https://github.com/pkimber/salt/blob/master/uwsgi/requirements3.txt
VPN (Wireguard)
responses
If you get the call doesn’t match any registered mock:
requests.exceptions.ConnectionError: Connection refused by Responses - the call doesn't match any registered mock.
Request:
- POST http://localhost:8080/service/query/process-instances/
Available matches:
- POST http://localhost:8080//service/query/process-instances/ URL does not match
Then the issue will be an empty settings.ACTIVITI_PATH.
To solve the issue, set the following environment variables:
# .env.fish
set -x ACTIVITI_PATH "flowable-rest"
# .gitlab-ci.yml
- export ACTIVITI_PATH=flowable-rest
# settings/base.py
ACTIVITI_PATH = get_env_variable("ACTIVITI_PATH")
Wagtail
Windows
Issue with time when dual booting
To correctly synchronise the time in windows when dual booting start
regedit and navigate to:
HKEY_LOCAL_MACHINE\SYSTEM\CurrentControlSet\Control\TimeZoneInformation
Right click anywhere in the right pane and choose New | DWORD (32-bit) Value. Name it:
RealTimeIsUniversal
then double click on it and give it a value of 1
see Incorrect Clock Settings in Windows When Dual-Booting with OS X or Linux